select 찾고자 하는 필드 from 테이블
* == 모든 필드
Where 절은, Select 쿼리문으로 가져올 데이터에 조건을 걸어주는 것을 의미.
| select 찾고자 하는 필드 from 테이블 where 필드, 조건 |
조건 목록
- 같지않음 : !=
- 범위 : between '범위 시작' and '범위 끝++'
- 포함 : in
- 패턴(문자열 규칙) : like '%문자열'
|
- etc
| select 필드 from 테이블 limit 가져오고 싶은 숫자 |
일부 데이터만 가져오기 |
| select distinct 필드 from 테이블 | 중복 데이터는 제외하고 가져오기 |
| select count(필드) from 테이블 | 데이터의 개수를 확인하여 가져오기 |
Group by는 동일한 범주를 갖는 데이터를 하나로 묶어서, 범주별 통계를 내주는 것
| select 범주별로 세어주고 싶은 필드, count(*) from 테이블명 group by 범주별로 세어주고 싶은 필드 쿼리가 실행되는 순서: from → group by → select |
| 최솟값 | count → min |
| 최댓값 | count → max |
| 평균 | count → mvg |
| 합 | count → sum |
Order by는 결과를 정렬
| select 원하는 필드 from 테이블명 order by 정렬의 기준이 될 필드 쿼리가 실행되는 순서: from → select → order by select 찾고자하는 필드 from 테이블 where 필드, 조건 group by 범주별로 세어주고 싶은 필드 order by 정렬의 기준이 될 필드 쿼리가 실행되는 순서: from → where → group by → select→ order by |
| 내림차순 | desc |
Join은 두 테이블의 공통된 정보 (key값)를 기준으로 테이블을 연결해서 한 테이블처럼 보는 것을 의미
| select 원하는 필드 from 기준이 되는 테이블 a join의 종류 join 연결하고 싶은 테이블 b on a.공통된 필드 = b. 공통된 필드 연결의 기준이 되고싶은 테이블을 from 절에, 연결해서 붙이고 싶은 테이블을 Join 절에 위치 쿼리가 실행되는 순서: from → join → select Ex) select u.name, count(u.name) as count_name from orders o inner join users u on o.user_id = u.user_id where u.email like '%naver.com' group by u.name 쿼리가 실행되는 순서: from → join → where → group by → select
|
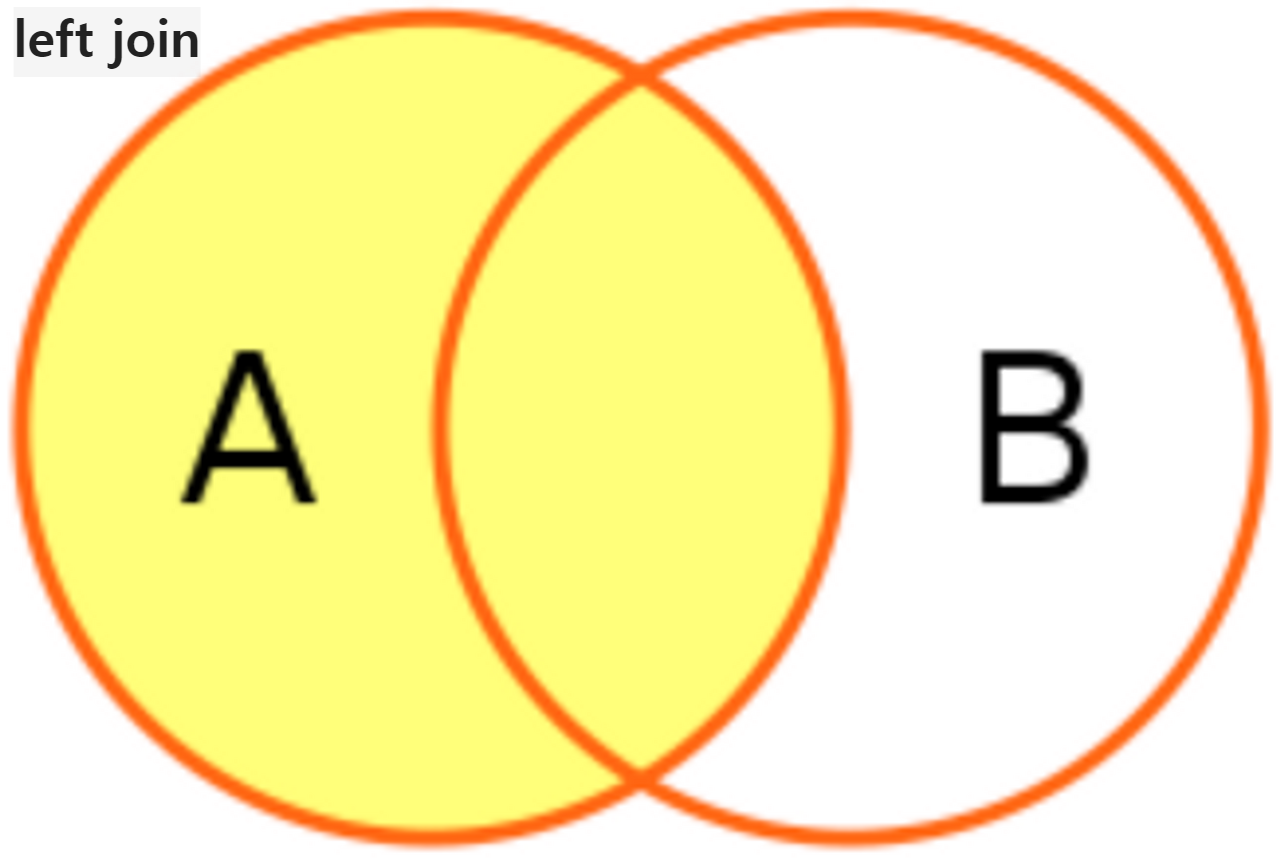
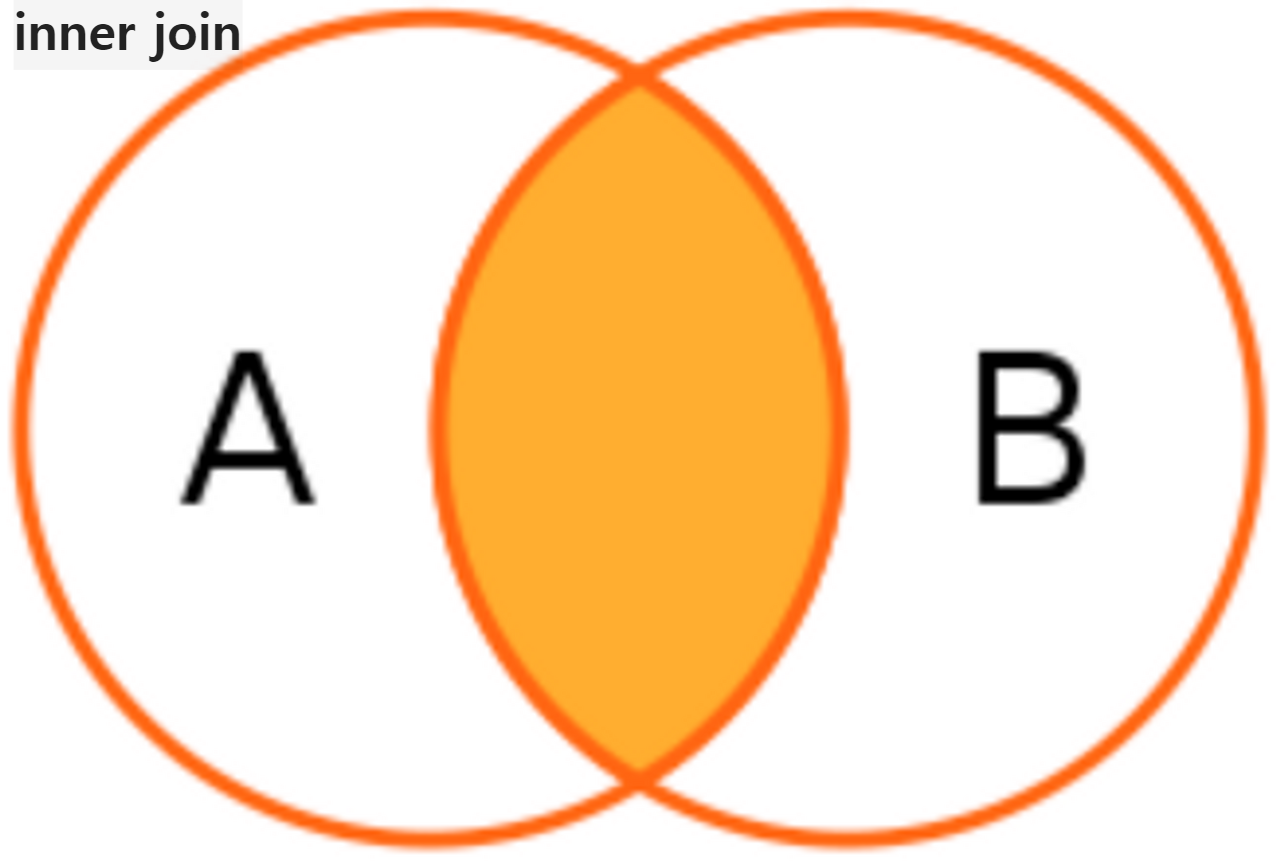
Union은 결과물 합치기
| ( 쿼리 ) union all ( 쿼리 ) union을 사용하면 내부 정렬이 먹지 않음 |
Subquery는 쿼리 안의 쿼리
| Where 에 들어가는 subquery wheren 필드명 in (subquery) Ex) 카카오페로 결제한 주문건 유저들만, 유저 테이블에서 출력하고 싶을 때 select * from users u where u.user_id in ( select o.user_id from orders o where o.payment_method = 'kakaopay' ) 실행순서 (1) from 실행: users 데이터를 출력 (2) Subquery 실행: 해당되는 user_id의 명단을 출력 (3) where .. in 절에서 subquery의 결과에 해당되는 'user_id의 명단' 조건으로 필터링 해줌 (4) 조건에 맞는 결과 출력 Select에 들어가는 subquery select 필드명,필드명,(subquery) from Ex) 공감 수가 본이 평소에 받았던 공감수에 비해 얼마나 높고 낮은지에 대해 알고 싶을 때 select c.checkin_id, c.user_id, c.likes, ( select avg(likes) from checkins c2 where c2.user_id = c.user_id ) as avg_like_user from checkins c 실행순서 (1) select * from 문에서 데이터를 한줄한줄 출력 (2) select 안의 subquery가 매 데이터 한줄마다 실행 (3) 그 데이터 한 줄의 user_id를 갖는 데이터의 평균 좋아요 값을 subquery에서 계산 (4) 함께 출력 From 에 들어가는 Subquery 내가 만든 select와 이미 있는 테이블을 join하고 싶을 때 사용 select 필드명,필드명 from 테이블 join 종류 join ( subquery ) a on 공통된 필드명 = 공통된 필드명 Ex) 1. 유저 별 공감수 평균 select user_id, round(avg(likes),1) as avg_like from checkins group by user_id 2.해당 유저 별 포인트 select pu.user_id, a.avg_like, pu.point from point_users pu inner join ( select user_id, round(avg(likes),1) as avg_like from checkins group by user_id ) a on pu.user_id = a.user_id 실행순서 (1) 먼저 서브쿼리의 select가 실행 (2) 이것을 테이블처럼 여기고 밖의 select가 실행 With절 복잡한 subquery는 쿼리문 앞에 with table1 as ( 쿼리문 ), table2 as ( 쿼리문 ) select 필드명 from table1 a inner join table2 b on 공통된 필드명 = 공통된 필드명 ... 으로 가독성 좋게 쓸 수 있음 |
문자열 다루기
이메일에서 아이디만 가져오기
select 필드명, email, SUBSTRING_INDEX( email, '@', 1) from 테이블
@를 기준으로 텍스트를 나누고 그 중 첫 번째 조각을 가져오는 의미
이메일에서 도메인만 가져오기
select 필드명, email, SUBSTRING_INDEX( email, '@', -1) from 테이블
@를 기준으로 텍스트를 나누고 그 중 마지 조각을 가져오는 의미
일부는 SUBSTRING(필드명, 시작하는 문자의 순서, 끝나는 문자의 순서)
Case는 경우에 따라 원하는 값을 새 필드에 출력하기
select 필드명, 필드명
case when 필드명 > 특정 기준 then 원하는 값
else 원하는 값
end as 새로운 필드명
from 테이블

